

先写
这个故事主要介绍了在网页上部署模型的来龙去脉。您也许可以在这里找到您想问的问题的答案。
在这个人工智能内容生成横行的时代,仍然有一群人“愚蠢地”坚持原创。如果您能读到最后,请点赞、收藏或关注我以支持我。谢谢( ̄︶ ̄)↗
我可以在网络上运行该模型吗?
丹尼尔:嘿,丹兄弟,你要去哪里散步?
蛋先生:我刚吃完饭,准备出去散步吃饭。
丹尼尔:我们一起去吧。丹哥,我最近有点迷恋AI,突然灵机一动。您认为我们可以在网页上运行机器学习模型吗?
蛋先生:嗯,确实如此。
为什么我可以在网络上运行模型?
丹尼尔:这让我想知道。专门用于查看网页的浏览器如何“兼职”运行模型?丹哥快告诉我
蛋先生:你想一下,一颗种子能否发芽,取决于它是否有合适的生存环境。对于模型来说也是如此。要有可以运行的“土壤”——运行时,还要有足够的“阳光”和“水”——即计算能力和存储。
丹尼尔:哦,我想我明白了。但我还是不明白浏览器是如何做到这一点的
蛋先生:自从浏览器有了WebAssembly之后,它的“胃口”就变大了!如今,许多用 C、C++、Rust 等编程语言编写的应用程序都可以编译为 WASM 格式并在浏览器中运行。这使得浏览器能够处理更复杂的计算任务
丹尼尔:没错!也就是说,原本用C++编写的模型运行时现在可以直接放入浏览器中,成为模型的“土壤”!
蛋先生:敌人!而且,浏览器的WebGL和WebGPU技术还可以让您的应用程序使用GPU资源,使得速度更高!否则,它可以运行,但会很慢,而且没有意义。
丹尼尔:哈哈,让我总结一下。 WebAssembly使模型成为可能,WebGL和WebGPU使计算能力的提高成为可能!
蛋先生:不错,总结得很好!
为什么要在浏览器中运行?
蛋先生:那我问你,为什么要在浏览器上运行模型?
丹尼尔:嗯~,这个~,我觉得蛮酷的!但说实话,我还真没有认真思考过这个问题。丹兄弟,你能告诉我吗?
丹先生:来吧,让我们从请求链接开始。如果模型部署在浏览器上,是不是就不需要请求服务器了?
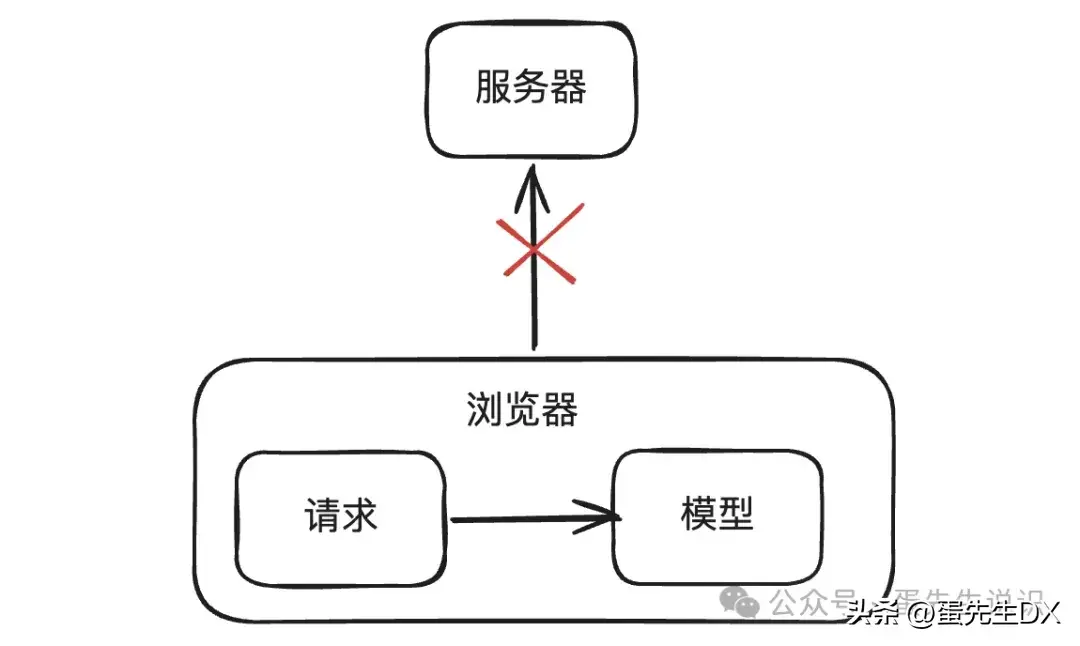
丹尼尔:那是肯定的
Dan先生:对于客户端来说,请求不会离开用户设备。这样会更好地保护用户隐私吗?
丹尼尔:是的
Dan先生:计算是在浏览器本地进行的,离用户更近,不会有网络请求的损失。响应速度通常更快。这会改善用户体验吗?
丹尼尔:是的
Dan先生:另外,模型已经部署在浏览器中了。只要应用本身支持离线访问,就可以离线使用吗?
丹尼尔:是的
Dan先生:对于服务器来说,因为计算压力被分担出去了,是不是可以减轻服务器的计算压力,降低运营成本呢?
丹尼尔:是的
蛋先生:剩下的你自己想办法吧。
如何在浏览器中运行它?
Daniel:好的,那么如何实现呢?
Dan先生:主流的机器学习框架除了训练模型之外,还可以部署和推理模型。比如著名的Tensorflow有tensorflow.js,可以将模型部署在浏览器端。但今天我要告诉大家的是onnxruntime-web
丹尼尔:onnxruntime-web?这个名字听起来有点新鲜!
Dan先生:onnxruntime-web,你可以把它拆成onnx、onnxruntime和onnxruntime-web。
丹尼尔:你继续
Dan先生:onnx是一种模型格式,就像你用来存储音乐的mp3格式一样,但它存储的是机器学习模型; onnxruntime 是运行这些模型的“玩家”;而onnxruntime-web允许这个“播放器”是一个神奇的工具,可以在网页上运行
丹尼尔:哦,模型有哪些格式?使用这个onnx有什么好处?
蛋先生:俗话说,合久则散;合则久则散。如果我们长期分裂,我们就会团结起来。
丹尼尔:这是要讲三国的节奏吗?
Dan先生:每个机器学习框架都有自己的模型格式。在onnx之前,您必须使用tf来部署tensorflow模型,并使用pytorch来部署pytorch模型。但用户只想部署一个模型。问题可以简化吗?
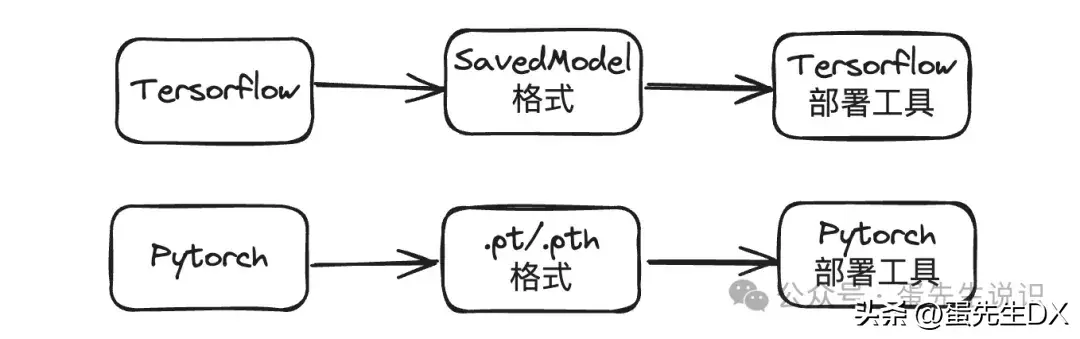
丹尼尔:确实如此
Dan 先生:所以就有了 onnx 的开放标准。每个公司的模型格式都可以转换成这个标准格式,然后就可以使用onnxruntime来部署和推断模型!
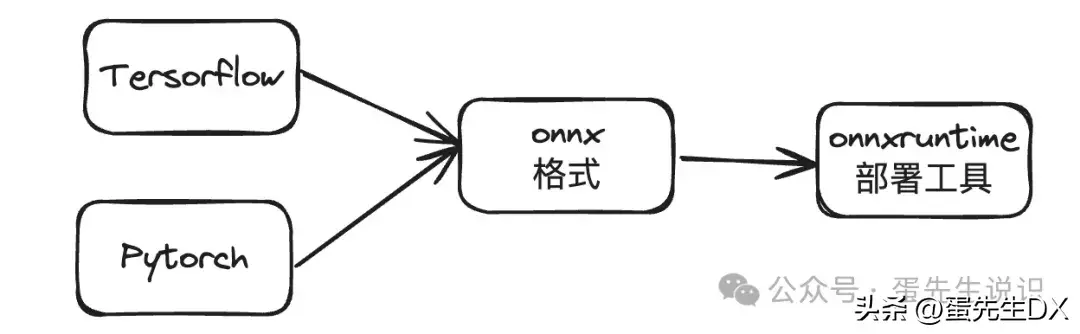
Daniel:那么这个onnxruntime是用来实现什么呢?
Egg先生:它是用C++实现的,在浏览器运行时会编译成WASM格式。然后onnxruntime-web提供JS API与WASM交互
丹尼尔:没错!然后给我看一个代码示例,我等不及了
Dan先生:下面是一个简单的数字图像识别的例子,但是接口有点低级。您需要了解张量之类的东西。希望将来有一个第三方库能够封装一个高级的接口,比如手写数字识别,输入是图片,输出是数字;对于生成式人工智能,输入是提示,输出是答案。当然你也可以自己尝试一下

...
...
...
有什么限制?
Daniel:除了数字识别之外,你还有什么其他的技巧吗?
蛋先生:当然!语音识别、图像分类、物体检测,甚至生成式人工智能都没问题!
丹尼尔:哇,你能处理大型语言模型吗?
Mr. Egg:但是在浏览器上运行时有一些小限制。
Daniel:我猜一下,模型的尺寸有限制吗?
蛋先生:敌人
丹尼尔:它能有多大?
Mr. Egg:首先我们要加载远程模型
所有主流浏览器都对 ArrayBuffer 的大小有限制。例如,Chrome 就是 2G。当使用fetch加载模型时,需要使用response.arrayBuffer()。如果型号超过2G就GG了。
另外,ONNX模型通过protobuf格式传输,单个protobuf消息的大小限制正好是2G。
Daniel:所以你最多只能加载2G的模型?
蛋先生:这并不完全正确。如果一次不行的话,我们可以分批进行!我们可以将模型分为模型图和权重,权重信息可以作为外部数据单独加载。只要模型图片不超过2G,我们就可以突破2G的限制。
Daniel:不是可以加载超大模型吗?
蛋先生:呵呵,别高兴得太早。模型最终加载到运行时环境中,而我们的运行时是在WebAssembly环境中。根据WebAssembly规范,Memory对象的大小最多为4G。所以理论上4G是天花板
丹尼尔:噢...
Egg先生:而且,当模型太大时,对硬件的要求就更高。不建议在浏览器里去乱搞这些大家伙。
丹尼尔:明白了,那我试试
蛋先生:好的,祝你好运!
写在最后
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:https://www.fwsgw.com/a/sanguo/208743.html